Dissimilarity index is a measure of segregation. It runs as follows:
where:


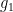
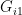
from which dissimilarity is being measured against
The measure suffers from a couple of issues:
- Concerns about lumpiness. Even in a small area, are black people at one end, white people at another?
- Choice of baseline. If the larger area (say a state) is 95\% white (Iowa is 91.3% White), dissimilarity is naturally likely to be small.
One way to address the concern about lumpiness is to provide an estimate of the spatial variance of the quantity of interest. But to measure variance, you need local measures of the quantity of interest. One way to arrive at local measures is as follows:
- Create a distance matrix across all addresses. Get latitude and longitude. And start with Euclidean distances, though smart measures that take account of physical features are a natural next step. (For those worried about computing super huge matrices, the good news is that computation can be parallelized.)
- For each address, find n closest addresses and estimate the quantity of interest. Where multiple houses are similar distance apart, sample randomly or include all. One advantage of n closest rather than addresses in a particular area is that it naturally accounts for variations in density.
But once you have arrived at the local measure, why just report variance? Why not report means of compelling common-sense metrics, like the proportion of addresses (people) for whom the closest house has people of another race?
As for baseline numbers (generally just a couple of numbers): they are there to help you interpret. They can be brought in later.