Macro Concerns
- Lack of Incentives for Producing High-Quality Software. Software’s role in enabling and accelerating research cannot be overstated. But the incentives for producing software in academia are still very thin. One reason is that people do not cite the software they use; the academic currency is still citations.
- Lack Ways to Track the Consequences of Software Bugs (Errors). (Quantitative) Research outputs are a function of the code researchers write themselves and the third-party software they use. Let’s assume that the peer review process vets the code written by the researcher. This leaves code written by third-party developers. What precludes errors in third-party code? Not much. The code is generally not peer-reviewed though there are efforts underway. Conditional on errors being present, there is no easy way to track bugs and their impact on research outputs.
- Developers Lack Data on How the Software is Being (Mis)Used. The modern software revolution hasn’t caught up with the open-source research software community. Most open-source research software is still distributed as a binary and emits no logs that can be analyzed by the developer. The only way a developer becomes aware of an issue is when a user reports the issues. This leaves errors that don’t cause alerts or failures, e.g., when a user user passes data that is inconsistent with the assumptions made when designing the software, and other insights about how to improve the software based on usage.
Conventional Reference Lists Are the Wrong Long-Term Solution for #1 and #2
Unlike ideas, which need to be explicitly cited, software dependencies are naturally made explicit in the code. Thus, there is no need for conventional reference lists (~ a bad database). If all the research code is committed to a system like Github (Dataverse lacks the tools for #2) with enough meta information about (the precise version of the) third-party software being used, e.g., import statements in R, etc., we can create a system like the Github dependency graph to calculate the number of times software has been used (and these metrics can be shown on Google Scholar, etc.) and also create systems that trigger warnings to authors when consequential updates to underlying software are made. (See also https://gojiberries.io/2019/03/22/countpy-incentivizing-more-and-better-software/).
Conventional reference lists may however be the right short-term solution. But the goalpost moves to how to drive citations. One reason researchers do not cite software is that they don’t see others doing it. One way to cue that software should be cited is to show a message when the software is loaded — please cite the software. Such a message can also serve as a reminder for people who merely forget to cite the software. For instance, my hunch is that one of the stargazer has been cited more than 1,000 times (June 2023) is because the package produces a message .onAttach to remind the user to cite the package. (See more here.)
Solution for #3
Spin up a server that open source developers can use to collect logs. Provide tools to collect remote logs. (Sample code.)
p.s. Here’s code for deriving software citations statistics from replication files.








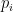 reflects the probability of donation from potential donor
reflects the probability of donation from potential donor  ,
, 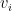 is the value of the donation from the ith customer,
is the value of the donation from the ith customer,  is the contingency fee, and
is the contingency fee, and 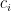 is the cost of reaching out to the potential donor.
is the cost of reaching out to the potential donor.