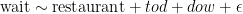Marketers love engagement ladders. To increase engagement with a product, many companies segment their users based on usage, for instance, into heavy (super), medium (average), and light, and prod their users to climb the ladder by suggesting they do things that people in the segment above them are doing and which they aren’t doing (as frequently).
At first blush, it sounds reasonable, even obvious. The trouble with the seemingly obvious, however, is that a) it gives the illusion of understanding, which prevents us from thinking carefully (because there is nothing more to understand!), and b) it doesn’t always make sense.
Let’s start by assuming that the ladder metaphor makes sense. The only thing that we need to do is to implement it correctly.
The ladder metaphor is built on the idea of stable rungs. If the classification into “light”, “medium”, and “heavy” is not durable—for instance, if someone classified as “heavy” can move to “light” next month on their own accord—what we learn by comparing “heavy” users to “medium” users may prove deleterious for the “medium” users.
Thus, it is useful to have stable rungs. To build stable rungs, start by assessing the stability of rungs by building transition matrices over time. If the rungs are not durable over time frames over which you want to see an effect, bolster them by extending the observation time over which usage is measured or using multiple measures. For instance, if usage over the last month does not produce durable rungs, it may be because usage is heavily seasonal. To fix that, switch to usage over multiple months or a seasonally adjusted number.
Once you have stable rungs, the next task is to come up with a set of actions that marketers can encourage users to take. The popular method to arbitrate between potential actions is to regress adjacent rungs on the set of potential actions and find the ones that are most highly correlated or have the highest beta. The popular method may seem reasonable but it isn’t. Assume away causality and you still care about how useful, actionable, and easy a recommended action is. The highest beta doesn’t mean the lowest cost per incremental improvement (again, assuming away causal concerns and taking betas at face value). And there is no way to address such concerns without experimenting and finding out what works best. (The message that works the best is a sum of the action being recommended and how that action is being encouraged.)
There is one minor nuance to the above. It pays to have ‘no action’ as an action if ‘no action’ isn’t your control group. Usage-based sorting merely sorts the users by kinds of people—by people who don’t need to use the product more often than thrice a month versus those who do. Who are we to say that they need to use the product more? Fact is that often enough the correlation between usage and retention is small. And doing nothing may prove better than annoying people with unwanted emails.
Lastly, the ladder metaphor leads some to believe that we need to stand up the same ladder for everyone. Using the highest beta or the most effective treatment means recommending the same (best) action to everyone. This is what I call the ‘mail merge’ heuristic. Mail merge is plausibly very highly correlated with the usage of MS-Word. But it would be an utter disaster if MSFT recommended it to me—I plan to quit the MSFT ecosystem if it comes to pass. Ideally, we want to encourage people to cross rungs by using more things in the software that are useful for them. (In fact, it isn’t clear how else we can induce a user to use the software more.) You can learn different ladders by modeling heterogeneity in treatment effects and then use simple algebra to find the best one for each person.