Let’s say that we want to measure the effect of a phone call encouraging people to register to vote on voting. Let’s define compliance as a person taking the call (like they do in Gerber and Green, 2000, etc.). And let’s assume that the compliance rate is low. The traditional way to estimate the effect of the phone call is via an RCT: randomly split the sample into Treatment and Control, call everyone in the Treatment Group, wait till after the election, and calculate the difference in the proportion who voted. Assuming that the treatment doesn’t affect non-compliers, etc., we can also estimate the Complier Average Treatment Effect.
But one way to think about non-compliance in the example above is as follows: “Buddy, you need to reach these people using another way.” That is a useful thing to know, but it is an observational point. You can fit a predictive model for who picks up phone calls and who doesn’t. The experiment is useful in answering how much can you persuade the people you reach on the phone. And you can learn that by randomizing conditional on compliance.
For such cases, here’s what we can do:
- Call a reasonably large random sample of people. Learn a model for who complies.
- Use it to target people who are likelier to comply and randomize post a person picking up.
More generally, the Average Treatment Effect is useful for global rollouts of one policy. But when is that a good counterfactual to learn? Tautologically, when that is all you can do or when it is the optimal thing to do. If we are not in that world, why not learn about—and I am using an example to be concrete—a) what is a good way to reach me? b) what message most persuades me? For instance, for political campaigns, the optimal strategy is to estimate the cost of reaching people by phone, mail, f2f, etc., estimate the probability of reaching each using each of the media, estimate the payoff for different messages for different kinds of people, and then target using the medium and the message that delivers the greatest benefit. (For a discussion about targeting, see here.)
Technically, a message could have the greatest payoff for the person who is least likely to comply. And the optimal strategy could still be to call everyone. To learn treatment effects among people who are unlikely to comply (using a particular method), you will need to build experiments to increase compliance. More generally, if you are thinking about multi-arm bandits or some such dynamic learning system, the insight is to have treatment arms around both compliance and message. The other general point, implicit in the essay, is that rather than be fixated on calculating ATE, we should be fixated on an optimization objective, e.g., the additional number of people persuaded to turn out to vote per dollar.
Sidebar
It is useful to think about the cost and benefit of an incremental voter. Let’s say you are a strategist for party p given the task of turning out voters. Here’s one way to think about the problem:
-
The benefit of turning out a voter in an election is not limited to the election. It also increases the probability of them turning out in the next election. The benefit is pro-rated by the voter’s probability of voting for party p.
-
The cost of turning out a voter is a sum of targeting costs and persuasion costs. The targeting costs could be the cost of identifying voters unlikely to vote unless contacted who would likely vote for party p or you could also build a model for persuadability and target further based on that. The persuasion costs include the cost of contacting the voter and persuading the voter
-
The cost of turning out a voter is likely greater than the cost of voting. For instance, some campaigns spend $150, some others think it is useful to spend as much as $1000. If cash transfers were allowed, we should be able to get people to vote at much lower prices. But given cash transfers aren’t allowed, the only option is persuasion and that is generally expensive.
 users and that we can iterate over them using
users and that we can iterate over them using  . Let’s denote the total number of unique domains—domains visited by any of the
. Let’s denote the total number of unique domains—domains visited by any of the  . And let’s use
. And let’s use  to iterate over the domains. Let’s denote the number of visits to domain
to iterate over the domains. Let’s denote the number of visits to domain 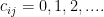 . And let’s denote the total number of unique domains a person visits (
. And let’s denote the total number of unique domains a person visits (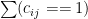 ) using
) using 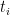 . Lastly, let’s denote predicted labels about whether or not each domain hosts pornography by
. Lastly, let’s denote predicted labels about whether or not each domain hosts pornography by  , so we have
, so we have 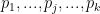 .
.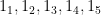 . Let’s say user one visits the first three sites once and let’s say that user two visits all five sites once. Given 10\% of the predictions are false positives, the total measurement error in user one’s score
. Let’s say user one visits the first three sites once and let’s say that user two visits all five sites once. Given 10\% of the predictions are false positives, the total measurement error in user one’s score 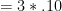 and the total measurement error in user two’s score
and the total measurement error in user two’s score  . The general point is that total false positives increase as a function of predicted
. The general point is that total false positives increase as a function of predicted 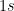 . And the total number of false negatives increase as the number of predicted
. And the total number of false negatives increase as the number of predicted 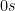 .
.
 is population of
is population of 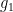 in the ith area
in the ith area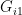 is population of
is population of 