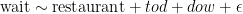Price dispersion is an excellent indicator of transactional frictions. It isn’t that absent price dispersion, we can confidently say that frictions are negligible. Frictions can be substantial even when price dispersion is zero. For instance, if the search costs are high enough that it makes it irrational to search, all the sellers will price the good at the buyer’s Willingness To Pay (WTP). Third world tourist markets, which are full of hawkers selling the same thing at the same price, are good examples of that. But when price dispersion exists, we can be reasonably sure that there are frictions in transacting. This is what makes the existence of substantial price dispersion on Amazon compelling.
Amazon makes price discovery easy, controls some aspects of quality by kicking out sellers who don’t adhere to its policies and provides reasonable indicators of quality of service with its user ratings. But still, on nearly all items that I looked at, there was substantial price dispersion. Take, for instance, the market for a bottle of Nature Made B12 vitamins. Prices go from $8.40 to nearly $30! With taxes, the dispersion is yet greater. If the listing costs are non-zero, it is not immediately clear why sellers selling the product at $30 are in the market. It could be that the expected service quality for the $30 seller is higher except that between the highest price seller and the next highest price seller, the ratings of the highest price seller are lower (take a look at shipping speed as well). And I would imagine that the ratings (and the quality) of Amazon, which comes in with the lowest price, are the highest. More generally, I have a tough time thinking about aspects of service and quality that are worth so much that the range of prices goes from 1x to 4x for a branded bottle of vitamin pills.
One plausible explanation is that the lowest price seller has a non-zero probability of being out of stock. And the more expensive and worse-quality sellers are there to catch these low probability events. They set a price that is profitable for them. One way to think about it is that the marginal cost of additional supply rises in the way the listed prices show. If true, then there seems to be an opportunity to make money. And it is possible that Amazon is leaving money on the table.
p.s. Sales of the boxed set of Harry Potter shows a similar pattern.